异常
异常的概念
Python 程序在运行时,如果解释器遇到一个错误,会停止程序的执行,并且提示一些错误信息,这就是 异常。程序停止执行并且提示错误信息这个动作,常称之为 抛出(raise)异常。
程序开发时,很难将所有的特殊情况都处理得面面俱到,通过 异常捕获 可以针对突发事件做集中的处理,从而保证程序的 稳定性 和 健壮性。
如需求是让用户输入一个整数:
num = int(input("输入一个整数:"))如果输入字母就会抛出异常: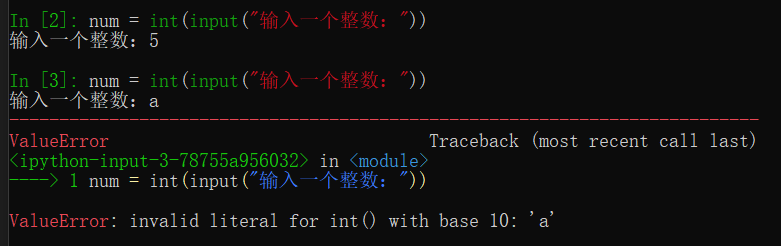
最简单的捕获异常
最简单的捕获异常语法格式:
try:
尝试执行的代码
except:
出现错误的处理try:
num = int(input("请输入数字:"))
except:
print("请输入正确的整数")except 下的语句执行完后,程序不会返回 请输入数字,而是继续执行下面的代码:
捕获不同错误类型的异常
try:
pass
except 错误类型1:
pass
except (错误类型2, 错误类型3):
pass
except Exception as result:
print("未知错误 %s" % result)错误类型是错误信息最后一行的第一个单词。
如:
1 / 0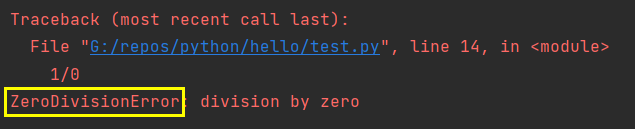
int("1.0")
例:提示用户输入一个整数,使用 8 除以用户输入的整数并且输出
try:
num = int(input("请输入整数:"))
result = 8 / num
print(result)
except ValueError:
print("请输入正确的整数")
except ZeroDivisionError:
print("除 0 错误")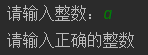
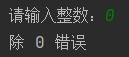
这样一来程序就不会因为异常而中断运行。
捕获未知错误
实际开发中很难预判到所有可能出现的错误。如果希望程序无论出现任何错误都不会因为 Python 解释器抛出异常而被终止,可以再增加一个 except:
except Exception as result:
print("未知错误 %s" % result)异常捕获完整语法
try:
# 尝试执行的代码
pass
except 错误类型1:
# 针对错误类型1,对应的代码处理
pass
except 错误类型2:
# 针对错误类型2,对应的代码处理
pass
except (错误类型3, 错误类型4):
# 针对错误类型3 和 4,对应的代码处理
pass
except Exception as result:
# 打印错误信息
print(result)
else:
# 没有异常才会执行的代码
pass
finally:
# 无论是否有异常,都会执行的代码
print("无论是否有异常,都会执行的代码")try:
num = int(input("请输入整数:"))
result = 8 / num
print(result)
except ValueError:
print("请输入正确的整数")
except ZeroDivisionError:
print("除 0 错误")
except Exception as result:
print("未知错误 %s" % result)
else:
print("正常执行")
finally:
print("执行完成")异常的传递
异常被传递到函数 / 方法的 调用方,如果传递到主程序,仍然没有异常处理,程序才会被终止。
所以根据异常的这种传递性,常把异常的捕获放在主函数。
def demo1():
return int(input("请输入一个整数:"))
def demo2():
return demo1()
try:
print(demo2())
except ValueError:
print("请输入正确的整数")
except Exception as result:
print("未知错误 %s" % result)抛出异常
在开发中,除了代码执行出错时 Python 解释器会抛出异常之外,还可以根据应用程序特有的业务需求 主动抛出异常。
Python 中提供了一个 Exception 异常类,在开发时,如果希望 抛出异常,可以:
- 使用
Exception类创建一个 异常对象 - 使用
raise关键字抛出这个异常对象
例:
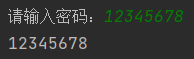
定义 input_password 函数,提示用户输入密码
- 如果用户输入长度 < 8,抛出异常
- 如果用户输入长度 >=8,返回输入的密码
def input_password():
pwd = input("请输入密码:")
if len(pwd) >= 8:
return pwd
# 密码长度不够,需要抛出异常
# 创建异常对象 - 使用异常的错误信息字符串作为参数
ex = Exception("密码长度不够")
raise ex
try:
user_pwd = input_password()
print(user_pwd)
except Exception as result:
print("发现错误:%s" % result)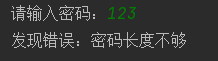
模块
模块的导入
每一个以扩展名 py 结尾的 Python 源代码文件都是一个 模块,模块名是一个 标识符,需要符合标识符的命名规则。
在模块中定义的 全局变量 、函数、类 都是提供给外界直接使用的 工具。这样一来,模块就好比是 工具包,要想使用这个工具包中的工具,就需要先 导入 这个模块。
import 模块名1
import 模块名2 import 模块名1 as 模块别名模块别名应符合大驼峰命名法。
import 模块名 是把模块中的工具全部导入,如果希望只导入 部分 工具,可以使用 from ... import 的方式:
from 模块名1 import 工具名这种使用 from 导入之后,使用模块中的工具就不需要通过 模块名.,而是可以直接使用工具名(全局变量、函数、类)。
如果两个模块存在 同名的函数,那么后导入模块的函数会覆盖掉先导入的函数。 所以 import 语句应该统一写在代码的顶部,更容易对比发现冲突。一旦发现冲突,可以使用 as 关键字起别名解决冲突。
可以使用 * 导入模块中所有工具:
from 模块名1 import *不过这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查。
模块文件的搜索顺序
Python 解释器在 导入模块 时,会先在 当前目录 搜索指定模块名的文件,如果没有,再搜索 系统目录。所以给模块文件起名时,尽量不要和系统的模块文件重名。
import random
print(random.randint(0, 10))如果当前目录下存在一个名为 random.py 的文件,Python 解释器会加载当前目录下的 random.py 而不是系统的 random 模块。
每一个模块都有一个内置属性 __file__ 可以查看模块的 完整路径
import random
print(random.__file__)
__name__ 属性
在导入文件时,文件中所有 没有缩进的代码 都会被执行一遍。
每一个模块是独立开发的,大多都有专人负责,开发人员通常会在模块下方增加一些测试代码,仅在模块内使用,而被导入到其他文件中不需要执行。
__name__ 是一个内置属性,记录一个 字符串,它可以让测试模块的代码只在测试情况下被运行,而在被导入时不会被执行。
如果是被其他文件导入的,__name__ 就是模块名;如果是在模块文件内,__name__ 是 __main__。
# 导入模块
# 定义全局变量
# 定义类
# 定义函数
# 在代码的最下方
def main():
pass
if __name__ == "__main__":
# 模块内测试代码
main()